Papers
papers
security
Identity Query Language Systems and Methods
Strata Identity, Inc. Pub. No.: US 2022/0318416 A1
A system, apparatus, and method for policy management is provided. The system,
apparatus, and method provide a universal policy management solution to unify
multiple bespoke systems to enable management of access and other policies
in distributed and/or heterogeneous environments. The system, apparatus,
and method uses or may be referred to as Identity Query Language or “IDQL.”
Policies and user access are defined centrally, and these policies are
distributed out to the various bespoke systems. This distribution is
aided by a policy gateway, or orchestrator, which acts as a policy
mapper and/or API wrapper which accepts IDQL policy configurations,
maps them to an imperative identity system, and carries out the IDQL
command in the identity systems' native API calls.

papers
telecommunications
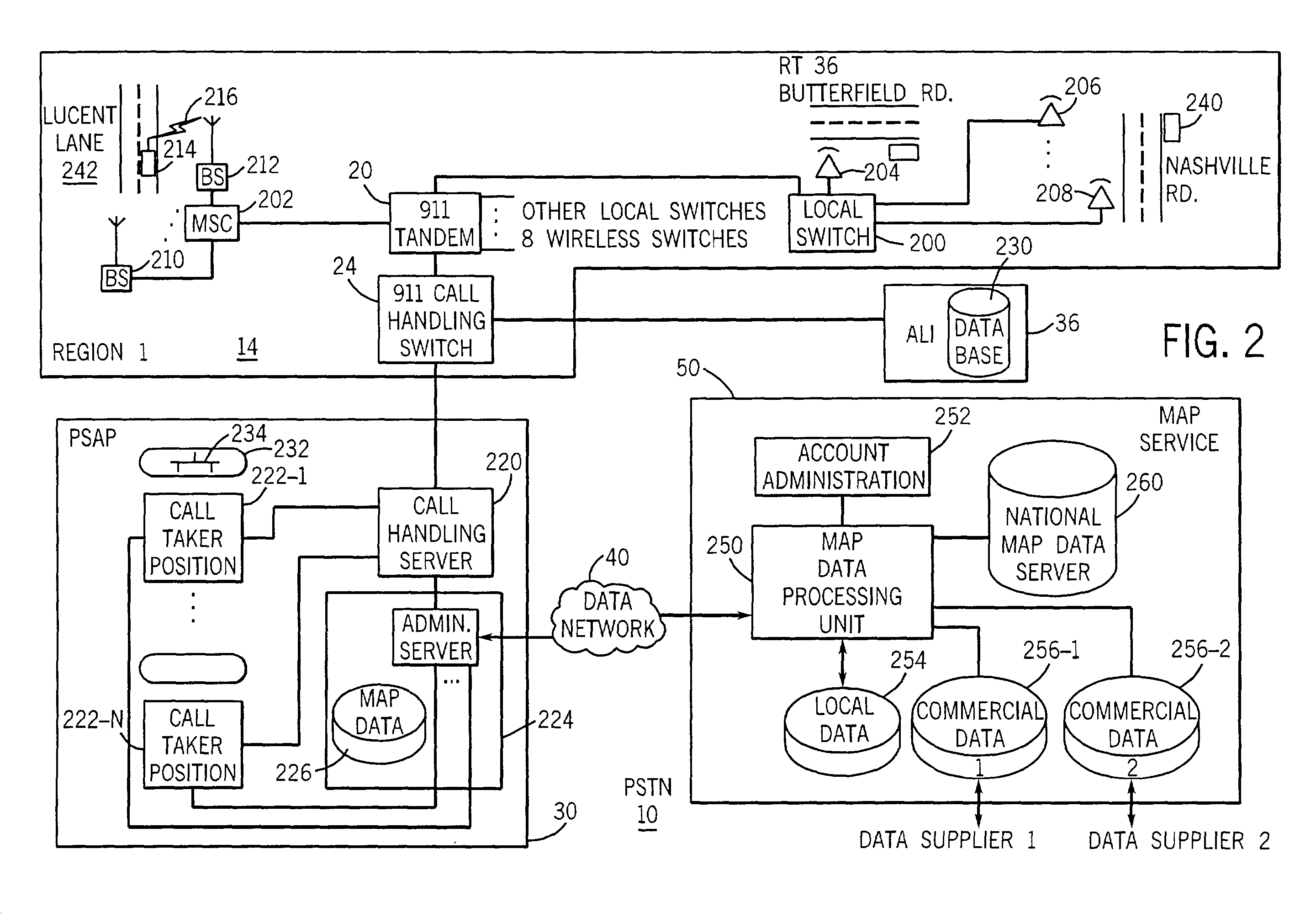
System and method for providing accurate local maps for a central
service
Lucent Technologies Inc. US 2004/0064256 A1
A system and method that provides economical and accurate data for a
selected area (jurisdiction) from a centralized location by generating
a base-line map from commercially available information and distributing
portions of this map to local jurisdictions. Inaccuracies and other
information only available locally are stored in a local database.
Periodically these databases are uploaded to a central location and
reconciled with the base line map. Advantageously, such reconciliation
may include a rules based reconciliation wherein the geo-coordinates
from the commercial vendors are used and applied to the local data.
A new base line map is then generated and distributed back to the
local user. In this manner, the local user has an accurate yet economical map.
papers
geology
Rocky Mountain Geology
The 1.4-Ga Mount Ethel pluton is a northeast-trending elliptical body of granodiorite to quartz
monzonite surrounded by Lower Proterozoic (1.8–1.7 Ga) rocks in the Park Range, northeast of Steamboat
Springs, Colorado. The contact along the northern and southern margins of the pluton is concordant with
the northeast-striking regional foliation, whereas the western margin is discordant to the regional
foliation. The southern margin of the pluton is adjacent to the subvertical, northeast-striking,
northwest-dipping Soda Creek–Fish Creek shear zone, which is located entirely within metasedimentary and
metavolcanic country rocks. Kinematic indicators within the shear zone yield a north-side-down sense of
shear with a left-lateral component. In contrast to several other well-studied 1.4-Ga plutons associated
with shear zones in the western U.S., penetrative strain related to the shear zone does not appear to
extend into the pluton. Late dikes, which appear to be genetically related to the Mount Ethel pluton,
cut the main penetrative fabric of the shear zone but are also offset by narrow, discontinuous mylonites
of the shear zone. Scarce discontinuous mylonites are also present along the southern margin of the
pluton. The pluton contains magmatic fabrics that parallel the strike of the shear zone along the north
and south margins of the pluton, but are at a high angle to it along the western margin. These data
suggest that early deformation associated with the Soda Creek-Fish Creek shear zone occurred prior to
pluton emplacement, that the Mount Ethel pluton was emplaced along a northeast-striking zone of
anisotropy, and that some shearing also took place after crystallization and cooling of the pluton.
Country rocks in the vicinity of the Mount Ethel pluton with garnet-biotite-plagioclasemuscovite ±
sillimanite have two generations of garnet: one that is syntectonic and another that is post-tectonic
relative to the northeast-striking foliation. Core compositions of pre/syntectonic garnet paired with
matrix biotite compositions yield temperatures of > 600°C at 5 kbar that are associated with early
(pre-Mount Ethel) deformation within the Soda Creek-Fish Creek shear zone. Core compositions of
post-tectonic garnet paired with matrix biotite compositions reveal a temperature gradient on the south
side of the pluton that increases from 540°C 5 km away to > 630°C within 1 km of the Mount Ethel pluton.
This may represent the thermal aureole around the intrusion, or it may represent a gradient that
pre-dated the pluton. Garnet-rim compositions from both syntectonic and post-tectonic garnet, paired
with compositions of biotite near garnet, yield consistent temperatures of 550 ± 50°C that are spatially
unrelated to the Mount Ethel pluton. These rim temperatures may be related to a third thermal event; or
alternatively, they may represent partial re-equilibration of garnet rims with nearby biotite during
cooling following the last metamorphism.
Posts
blog
platform
Fresh Cloud
Introduction
This article was first introduced as a lecture at the University of Colorado in the Spring of 2021. The
lecture was intended to give students a behind the scenes look at how a modern application platform
works.
Given that developer productivity and operator efficiency continues to remain top of mind for both
startup and enterprise companies alike, we thought that we would share the lecture as an article. The
open source projects included in the article are all part of the Cloud Native Computing Foundation.
History
Over the past few years, we have observed companies move away from multi-tenant platforms in favor of
public cloud providers that host Kubernetes as a service. An obvious driver being freedom of choice
around associated components contributing to their infrastructure. Another driver, public cloud
providers all agreed on a single container orchestration engine - Kubernetes. In the telecommunications
industry, we would call stand-alone Kubernetes basic dial tone. Just enough to establish basic phone
service. And similar to voicemail and the ability to make emergency calls, cloud providers have improved
upon basic dial tone - resulting in numerous tools and applications that are easy to integrate, intended
to significantly increase developer productivity and operator efficiency.
We have also seen a trend toward maintaining a Kubernetes cluster per team or even per application,
depending on the size of the application. The movement is possible largely because building a
self-service platform has become increasingly easy over the past several years due to the explosion of
open source within the platform engineering community. This is commonly referred to as DevOps or
DevSecOps.
The steps below will walk you through building a modern application platform, recently referred to as a
secure software supply chain.
here's a link to
the full article...
blog
architecture
Application Continuum
Introduction
I've recently been part of several discussions that argue for and against building applications with
Microservices. In response, I've introduced the below diagram and associated architecture to show the
evolution of a distributed system starting from a single application and evolving into several
applications and services. Starting with a single application is just as viable as starting with
Microservices, it simply depends on how much information you're given.
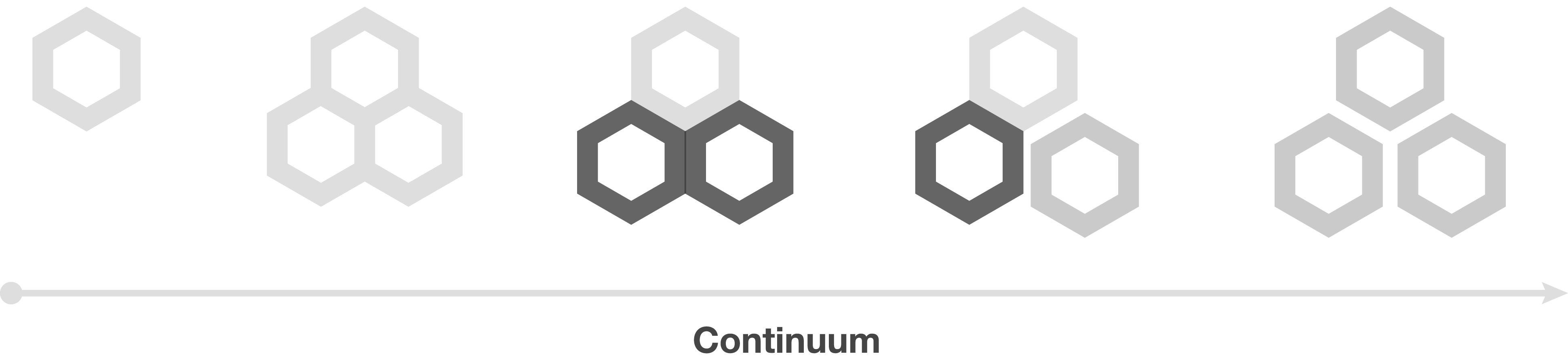
Projects could start anywhere on the continuum, typically driven by the amount of information a team has
about an application or set of applications. The amount of information is often driven by product/market
fit. The less you know about a given market, which is typically common for startups, the further left
you'd start. The more you know about a given market, the further right. Large, enterprise
business-to-business applications, for example, tend to experience low market risk but often face high
execution risk. Hence the tendency for enterprises to start on the far right of the continuum.
The continuum is language agnostic and applies to any modern programming language.
Why is all this important?
This architecture helps reduce the cost of changing code as customer needs evolve. It provided
developers and product owners the ability to use, reuse, and replace components within a given code base
to both pivot existing products and easily create new ones.
here's a link to
the full article...
blog
startups
Startup Recipe
If you’re thinking about starting a software project, here’s the recipe that I’ve been giving people for
years.
Have complete visibility into your feature backlog
Use a tool like Pivotal Tracker. Have 1 week iterations. Include features, chores, and bugs. Assign
points to features by estimating size and deriving duration. Work should be getting done (i.e. stories
should be marked as finished).
If work isn’t getting done (i.e. estimates are low an
iteration), this is a ‘smell’, something might be going wrong. Regularly review and accept the work the
developers are doing.
Outsource your infrastructure
Use a Platform as a Service (PaaS); sign up for an account on Google, Azure, or Amazon.
Use Google's G Suite; Gmail, Documents, etc.
Own your source code
Use git. Own your github account and give collaborator access to developers. Developers may move on or
off the project, but you’ll always have access to the code base.
Plan for multiple Environments
You should plan for 3 environments, Continuous Integration/Delivery (CI/CD), Review, and Production.
You’ll accept
stories in the review environment and push tagged releases to production.
Keep a high Bus Count
Rotate developers through your application feature set. Avoid siloing developers at all costs, “code
with a buddy”. Give complete infrastructure access to your developers (DNS, Google Apps/Email, and
infrastructure), trust them completely.
Write tests and setup a continuous integration and delivery environment
Tests are essential for describing application features and intentions within the code base. Tests are
essential for knowledge transfer between developers (it’s unlikely that you’ll have the same developer
on the project at all times). Tests give you the confidence to change product direction without breaking
or rewriting the entire code base. Without tests, you should quit now. (This is especially true for
interpreted languages like ruby). Test drive.
Keep the deployment process nimble
Because you are test driving and have continuous integration, you can deploy at any time. Give your
hosting credentials (engine yard, amazon, etc.) to your developers. They should be able to deploy to
review or production within minutes (not hours).
Invest in your team
Don’t let bad technology choices effect your startup, there are plenty of risks out there. Find a
platform and team that will guarantee minimal technical risk. There’s a huge difference developer skill
sets theses days. Find a great team and pay them well. Good software is expensive, build and invest in
your development team. Expect this to be your budget and hire generalists.
blog
startups
Scoping with Confidence
We’ve recently scoped several projects in Boulder. While scoping, several clients asked how we’re able
to estimate a project’s cost with such confidence. I’ve thought about this a bit and I actually think
this is pretty interesting and remarkably similar to something we’ve all been doing for a while:
estimating user stories in Tracker.
Scoping a project is very similar to determining the number of points or weight you might assign to a
user story or feature in an Agile backlog. Similar to measuring the relative size or complexity of a
feature, we’re just measuring the relative size or complexity of the project against similar projects
that we’ve completed. The important piece here is that we’re measuring against completed projects.
With stories or features you estimate size and then derive duration in order to achieve a running
feature velocity. Feature velocity is essential and the key to predictability. Completing features and
measuring their associated duration is the empirical data we use to determine when a future set of
stories will be completed or delivered. When scoping a project we’re missing this empirical data,
although we still need to actually provide a duration to calculate the project’s cost. So how do we
estimate a project’s scope and cost?
Imagine estimating a feature that you just completed for another project. You’d probably be pretty close
on the points assignment as well as confidence. Now apply this to a project. It’s becomes easier to
scope a project when you’ve completed a few similar projects. The more projects the better the
comparison and resultant estimate.
Completed projects are valuable because we know how long they took to complete. For example, client A’s
CRM was roughly 1 pair for 2 months. Client B’s CRM required 2 pairs for 4 months. And client C’s CRM,
the one we’re currently estimating, is slightly more complex than client A’s although much less complex
than client B’s. We’ll likely estimate client C’s CRM at 2 pairs for 2 months.
It’s actually not all gravy. There are several risks that may increase a project’s scope. For example,
if we’re up against an aggressive timeline, we may include an additional pair for a few weeks to help
increase feature velocity. Similarly, if there are complex integrations, like a 3rd party billing system
or external messaging subsystems, we may include an additional pair for a month.
During an initial scoping we help reveal or tease out high level risks and then prioritize theses risks
against constraints like timeline and budget. The more similar the risks we’ve resolved on completed
projects, the more confidence we have to estimate risks during a new project scoping. Again, pretty
similar to how we estimate features in a backlog. We’re just estimating the size or complexity of risks
against similar risks with known durations.